Data Structures & Algorithms
Home | Code Review | Databases | Software Engineering & Design | Data Structures & Algorithms
Narrative
The artifact I choose was the final project from CS 260 Data Structures and Algorithms. This was created last February 2019. The artifact was three different C++ codes the help manage bids using different data structures and algorithms. Each data structure and algorithm used was further explained. I chose this artifact because it allowed me to show my knowledge and experience using data structures and algorithms. It also allowed me to choose the use of a different programming language. This artifact embodies this specific category. To further this artifact, the inclusion of more types of data structures and algorithms will be used. Linear and binary searches, bubble and shell sorting, and AVL and spanning will be the additional algorithms and data structures that will be looked at.
The course outcome that aligns with it the most is “design and evaluate computing solutions that solve a given problem using algorithmic principles and computer science practices and standards appropriate to its solution, while managing the trade-offs involved in design choices.” This enhancement will accomplish this outcome because I will be going into detail as well as showing how each new algorithm or structure will be used. I will also exemplify the uses of the data structures and algorithms which will show my knowledge of making design choices. Another course outcome is “demonstrate an ability to use well-founded and innovative techniques, skills, and tools in computing practices for the purpose of implementing computer solutions that deliver value and accomplish industry-specific goals.” This artifact will show my ability to use the programming language C++ and data structures and algorithms accordingly. This ability will help accomplish industry goals like managing large amounts of data.
Originally, I had planned to include more data structures and algorithms into this artifact. As research and planning took place for this artifact, I began to realize that many of the data structures and algorithms I had planned to use are very similar to the ones I have already investigated previously. I decided to improve on my previous code as I thought it was enough in showing my knowledge in data structures and algorithms. I did try to implement another sorting technique in my code but had trouble implementing it correctly. In my opinion, it would be better to make my original code better than to implement a code that I was not confident in showing. As for the additional data structures and algorithms, I explained and detailed them further as well as show some examples of them. This artifact was more about perfecting and adding additional knowledge to the original artifact.
Enhancement Text
There are several data structures and algorithms that were explored using the programming language C++. The three data structures were vectors, hash tables, and tree structures. The algorithms explored were search, sort, and hashing/chaining. The following sections will analyze how each data structures and algorithms were used within the program and its effectiveness in performing the required function. The overall program was to display a list in which a user can view, load, remove, or update a list of bids. Some parts of the program were directed in sorting or editing the bidding list in specific ways.
I. Data Structures
Vectors are an ordered list of a certain data type (Zybooks, n.d., 2.6). They are very much alike arrays but can easily resize the list (2.7). A vector has a failsafe in which it checks whether an index is within the vector’s range. In an array, index four has the data 34 already stored. As the program continues, another data is set to index four and hence the data 34 will be overwritten by the new data. In VectorSorting, a vector was utilized to store the bids from the provided file. This data structure is better suited than using an array because a bid can be removed or added and checks the range.
Hash tables store unordered items by using a hash function to place an item into a location in a vector or array (5.1). This is a specific type of vector or array. It can store items in fewer locations. For instance, there are 300 integers. Typically, 300 indices are needed but by using a hash function, maybe only 10 indices are needed. In HashTable, the purpose of the program was to store the bids in a hash table and be able to display, find, and remove bids using that data structure. There are countless amounts of bids within the file. Being able to store them in fewer number of indices helps to find and remove certain bids faster. If there were 300 bids in a normal list, the program might have to search all 300 bids to find the right bid to display or remove which can take a long time. In a hash table, there might be only 25 indices and that means that is 275 less indices for the program to search. It is much faster to search 25 than 300 indices.
Binary trees were the focused tree structure used for the program. A node in a binary tree has up to two nodes or children (6.1). In a list, a node can only have one successor. A binary tree is great to use for searching as it minimizes the amount of comparisons that can be made (6.2). For example, there are 456 nodes. Within a list, a worst-case scenario is to compare the key with all 456 nodes. In a binary tree, a worst-case scenario would be [log (456)] + 1 which would be nine comparison to find the key. In BinarySearchTree, the options were the same as HashTable but uses a binary tree as the data structure. Using a binary search tree is effective in sorting the bids because it would require fewer comparisons making it faster to locate items.
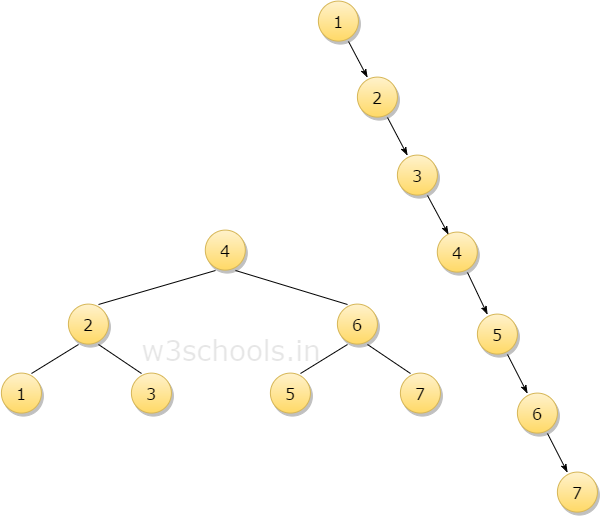
Vectors, hash tables, and binary trees are basic types of data structures. There are other types like stacks and AVL tree structures. Stacks is simply inserting or deleting data from one end. Think of a stack of plates. Plates are stacked on top of each other. An individual can remove the plate on the top or add to the top of the stack. It is not the most efficient data structure. The ideal application of stack is reversing a word or when the application needs to be backtracked. For instance, the application employs a list of tasks. Having the list of tasks as a stack can functions well to go back to the previous task. AVL tree structures is a specific type of binary tree (AVL, n.d.). The difference is that the height between the right and left subtrees are one or less. This allows for faster insertion or deletion because the amount of comparisons will be few. The diagram below shows an AVL tree to the left. If a user wanted to delete the seventh node, there would only need to be three comparisons in AVL tree. In the regular tree, there would be seven comparisons made.
II. Algorithms
Search is basically finding an item within a list or other data structures the match a given key (3.6). This is an important algorithm to have because users would want to find an item in a sea of data. Both in HashTable and BinarySearchTree, a search algorithm was used. When both programs were running and the option to find or remove a bid was executed, the program was able to do so. The program would search for the bid identification and if a bid from the file was a match, it would display or remove bid according to the operation. If there was no bid the matched the bid identification, a message would print saying a bid was not found.
Sorting is the process in which a list will be organized in ascending or descending order (4.5). There are a handful of ways to sort. In the program VectorSorting, selection and quicksort were used to sort the bids within the file. Selection sorting goes through the list and selects the proper item to insert next to make the list ordered (4.6). Quicksort breaks apart the list into a low and high part repeatedly and sorts each of the parts (4.11). Both these types of sort go about sorting a list in different ways but should end with the same result. This can be seen by the display of bids when running the program after sorting.
Hashing and chaining is the underlying algorithm that makes hash tables the way they are. There are several types of hashing like modulo, mid-square, and multiplicative string (5.4). Sometimes when hashing two items might end up in the same index which is a collision. Chaining is used resolves collision by creating a list within the index to store multiple items in one index (5.2). In HashTable, the hash function used was modulo 25. It would divide the bid identification by 25 and the remainder would be the index of the bid. When all the bids were displayed after hashing, some of the bids had the same key because chaining was used.
In addition to these algorithms, there a few other specific types of searches and sorts that will be explained. The other searches that will be talked about are linear and binary. A linear search is looking through the data sequentially (Searching Techniques, n.d.). This is not the most efficient way of searching as it would require numerous amounts of comparisons until a match is found. The binary search is the faster and more efficient search. The data must be sorted. It will compare the data from the beginning of the list and the middle of the list. If it does not find a match it will look split the list until it finds a match. An example of this type of search is used in the BinarySearchTree. There will be three different techniques of sorting which are bubble, merge, and insertion. Bubble sorting is taking the elements and placing it in ascending order (Bubble Sort, n.d.). It will start comparing at the first element and swap places accordingly until it has found its place in order. This is not the most efficient when dealing with massive amount of data because it will sort and compare an element from the start of a list. The next type of technique is merge. Merge sorting breaks down a list into similar sizes and sorts those lists before merging them back together (Merge Sort, n.d.). The last sorting technique is insertion. This technique is not very efficient as it requires to take one element and place it wherever it belongs. There is no organization and can be random.
III. Conclusion
Data structures are important when creating a program. There are many kinds of data structures and these programs only showcase some types. Many programs are created to deal with great amounts of data and being able to maintain that data is key. This is where data structures come into place as it makes it easy to maintain date. Once a programmer has implemented a data structure for instance a hash table that is how the data will be structured. Once it is organized that way, it cannot be changed unless a new code is created. The biggest impact on which data structure to choose is how fast an item can be searched or removed. Using vector can take forever to search an item within a great amount of information. A hash table or a tree structure would be ideal when dealing with big data. When running HashTable or BinarySearchTree, the amount it takes to search or remove a bid can vary. This can be seen in the resulting time printed.
Algorithms are the underlying power to data structures. Without hashing, sorting, or searching, data structures are only good to organize data. As previously stated, dealing with big data is an issue. Using algorithms like hashing can ease the load. It compacts the amount of data to fewer indices which in turn make for faster searching and takes less memory. These things effect the efficiency and effectiveness of a program. Algorithms allow to organize and search for specific data. For instance, in VectorSorting the list of bids from the file was not ordered and using a sorting algorithm, the program was able to sort them in ascending order. This is helpful especially in this scenario has it is good to know who the highest and lowest bids are.
References
AVL Trees in Data Structures. (n.d.). Retrieved from https://www.w3schools.in/data-structures-tutorial/avl-trees/
Bubble Sort Algorithm in Data Structures. (n.d.). Retrieved from https://www.w3schools.in/data-structures-tutorial/sorting-techniques/bubble-sort-algorithm
Insertion Sort Algorithm in Data Structures. (n.d.). Retrieved from https://www.w3schools.in/data-structures-tutorial/sorting-techniques/insertion-sort-algorithm/
Merge Sort Algorithm in Data Structures. (n.d.). Retrieved from https://www.w3schools.in/data-structures-tutorial/sorting-techniques/merge-sort-algorithm/
Searching Techniques in Data Structures. (n.d.). Retrieved from https://www.w3schools.in/data-structures-tutorial/searching-techniques/ Zybooks: CS-260: Data Structures. (n.d.). Retrieved from https://learn.zybooks.com/zybook/SNHUCS260AY16-17
Code
Vector Sorting
Complete Vector Sorting Code
//Implement the quick sort logic over bid.title
/**
* Partition the vector of bids into two parts, low and high
*
* @param bids Address of the vector<Bid> instance to be partitioned
* @param begin Beginning index to partition
* @param end Ending index to partition
*/
int partition(vector<Bid>& bids, int begin, int end) {
int midpoint = begin + (end - begin) / 2;
Bid pivot = bids.at(midpoint);
int x = begin;
int y = end;
bool done = false;
while(!done){
while(bids.at(x).title.compare(pivot.title) == -1){
++x;
}
while(pivot.title.compare(bids.at(y).title) == -1){
--y;
}
if(x>=y){
done = true;
}
else{
Bid temp = bids.at(x);
bids.at(x) = bids.at(y);
bids.at(y) = temp;
++x;
--y;
}
}
return y;
}
/**
* Perform a quick sort on bid title
* Average performance: O(n log(n))
* Worst case performance O(n^2))
*
* @param bids address of the vector<Bid> instance to be sorted
* @param begin the beginning index to sort on
* @param end the ending index to sort on
*/
void quickSort(vector<Bid>& bids, int begin, int end) {
int pivot = 0;
if(begin >= end){
return;
}
pivot = partition(bids, begin, end);
quickSort(bids, begin, pivot);
quickSort(bids, pivot + 1, end);
}
//Implement the selection sort logic over bid.title
/**
* Perform a selection sort on bid title
* Average performance: O(n^2))
* Worst case performance O(n^2))
*
* @param bid address of the vector<Bid>
* instance to be sorted
*/
void selectionSort(vector<Bid>& bids) {
for(int i = 0; i < bids.size(); ++i){
int indexSmallesTitle = i;
for(int j = i + 1; j < bids.size(); ++j){
if(bids.at(indexSmallesTitle).
title.compare(bids.at(j).title) == 1){
indexSmallesTitle = j;
}
}
Bid temp = bids.at(i);
bids.at(i) = bids.at(indexSmallesTitle);
bids.at(indexSmallesTitle) = temp;
}
}
Implementation of Sorts in Main Method
// Selection sort and report timing results
case 3:
ticks = clock();
selectionSort(bids);
ticks = clock() - ticks;
cout << bids.size()
<< " bids sorted" << endl;
cout << "time: "
<< ticks << " clock ticks" << endl;
cout << "time: "
<< ticks * 1.0 / CLOCKS_PER_SEC << " seconds" << endl;
break;
// Quick sort and report timing results
case 4:
ticks = clock();
quickSort(bids, 0, bids.size() - 1);
ticks = clock() - ticks;
cout << bids.size() << " bids sorted" << endl;
cout << "time: " << ticks
<< " clock ticks" << endl;
cout << "time: "
<< ticks * 1.0 / CLOCKS_PER_SEC << " seconds" << endl;
break;
}
}
Binary Search Tree
Complete Binary Search Tree Code
//Internal structure for tree node
struct Node {
Bid bid;
Node* parentPtr;
Node* leftPtr;
Node* rightPtr;
};
//=========================================================
// Binary Search Tree class definition
//=========================================================
/**
* Define a class containing data members and methods to
* implement a binary search tree
*/
class BinarySearchTree {
private:
Node* root;
void addNode(Node* node, Bid bid);
void inOrder(Node* node);
Node* removeNode(Node* node, string bidId);
public:
BinarySearchTree();
virtual ~BinarySearchTree();
void InOrder();
void Insert(Bid bid);
void Remove(string bidId);
Bid Search(string bidId);
};
/**
* Default constructor
*/
BinarySearchTree::BinarySearchTree() {
// initialize housekeeping variables
root = nullptr;
}
/**
* Destructor
*/
BinarySearchTree::~BinarySearchTree() {
// recurse from root deleting every node
}
/**
* Traverse the tree in order
*/
void BinarySearchTree::InOrder() {
}
/**
* Insert a bid
*/
void BinarySearchTree::Insert(Bid bid) {
//Implement inserting a bid into the tree
if (root == nullptr) {
root = new Node;
root->bid = bid;
root->leftPtr = nullptr;
root->rightPtr = nullptr;
root->parentPtr = nullptr;
}
else {
addNode(root, bid);
}
}
/**
* Remove a bid
*/
void BinarySearchTree::Remove(string bidId) {
//Implement removing a bid from the tree
Node* nodePtr = Remove(root, bidId);
if (nodePtr == nullptr) {
return;
}
else {
nodePtr->parentPtr->leftPtr = nodePtr->leftPtr;
nodePtr->parentPtr->rightPtr = nodePtr->rightPtr;
nodePtr->leftPtr->parentPtr = nodePtr->parentPtr;
nodePtr->rightPtr->parentPtr = nodePtr->parentPtr;
delete nodePtr;
}
}
/**
* Search for a bid
*/
Bid BinarySearchTree::Search(string bidId) {
//Implement searching the tree for a bid
Node* nodePtr = Search(root, bidId);
if (nodePtr == nullptr) {
Bid bid;
return bid;
}
else {
return nodePtr->bid;
}
Bid bid;
return bid;
}
/**
* Add a bid to some node (recursive)
*
* @param node Current node in tree
* bid Bid to be added
*/
void BinarySearchTree::addNode(Node* node, Bid bid) {
//Implement inserting a bid into the tree
int curKey = atoi(node->bid.bidId.c_str());
int key = atoi(bid.bidId.c_str());
cout << "Current key is: " << curKey << endl;
cout << "Search key is: " << key << endl;
if (key > curKey) {
if (node->rightPtr == nullptr) {
node->rightPtr = new Node;
node->rightPtr->bid = bid;
node->rightPtr->rightPtr = nullptr;
node->rightPtr->leftPtr = nullptr;
node->rightPtr->parentPtr = node;
}
else {
addNode(node->rightPtr, bid);
}
}
else {
if (node->leftPtr == nullptr) {
node->leftPtr = new Node;
node->leftPtr->bid = bid;
node->leftPtr->rightPtr = nullptr;
node->leftPtr->leftPtr = nullptr;
node->leftPtr->parentPtr = node;
cout << "leftPtr is nullptr" << endl;
}
else {
cout << "leftPtr is NOT nullptr" << endl;
addNode(node->leftPtr, bid);
}
}
}
void BinarySearchTree::inOrder(Node* node) {
}
Implementation of Binary Search Tree in Main Method
// Define a binary search tree to hold all bids
BinarySearchTree* bst;
//Load Bids
case 1:
bst = new BinarySearchTree();
// Initialize a timer variable before loading bids
ticks = clock();
// Complete the method call to load the bids
loadBids(csvPath, bst);
//cout << bst->Size() << " bids read" << endl;
// Calculate elapsed time and display result
ticks = clock() - ticks;
// current clock ticks minus starting clock ticks
cout << "time: " << ticks
<< " clock ticks" << endl;
cout << "time: " << ticks * 1.0 / CLOCKS_PER_SEC
<< " seconds" << endl;
break;
//Display All bids
case 2:
bst->InOrder();
break;
//Search Bids
case 3:
ticks = clock();
bid = bst->Search(bidKey);
ticks = clock() - ticks;
// current clock ticks minus starting clock ticks
if (!bid.bidId.empty()) {
displayBid(bid);
} else {
cout << "Bid Id " << bidKey << " not found." << endl;
}
cout << "time: " << ticks
<< " clock ticks" << endl;
cout << "time: " << ticks * 1.0 / CLOCKS_PER_SEC
<< " seconds" << endl;
break;
//Delete Bids
case 4:
bst->Remove(bidKey);
break;
}
Hash Table
Complete Hash Table Code
//===========================================================
// Hash Table class definition
//===========================================================
/**
* Define a class containing data members and methods to
* implement a hash table with chaining.
*/
class HashTable {
private:
// Define structures to hold bids
vector<list<Bid>> bids;
unsigned int hash(int key);
public:
HashTable();
virtual ~HashTable();
void Insert(Bid bid);
void PrintAll();
void Remove(string bidId);
Bid Search(string bidId);
};
/**
* Default constructor
*/
HashTable::HashTable() {
//Initialize the structures used to hold bids
bids.resize(17939);
}
/**
* Destructor
*/
HashTable::~HashTable() {
// Implement logic to free storage
when class is destroyed
bids.clear();
delete &bids;
}
/**
* Calculate the hash value of a given key.
* Note that key is specifically defined as
* unsigned int to prevent undefined results
* of a negative list index.
*
* @param key The key to hash
* @return The calculated hash
*/
unsigned int HashTable::hash(int key) {
// Implement logic to calculate a hash value
int hashVal = 25;
int hash = key % hashVal;
return hash;
}
/**
* Insert a bid
*
* @param bid The bid to insert
*/
void HashTable::Insert(Bid bid) {
// Implement logic to insert a bid
int id = stoi(bid.bidId);
int key = hash(id);
Bid currentNode;
currentNode = bid;
bids.at(key).push_back(currentNode);
}
/**
* Print all bids
*/
void HashTable::PrintAll() {
//Implement logic to print all bids
for(int i = 0; i < bids.size(); ++i){
if(bids.at(i).size() > 0){
for(auto j : bids.at(i))
cout << "Key "<< i << ":
| "<<j.bidId<< "
| "<< j.title << "
| "<<j.amount << "
| " << j.fund << endl;
}
}
}
/**
* Remove a bid
*
* @param bidId The bid id to search for
*/
void HashTable::Remove(string bidId) {
// Implement logic to remove a bid
int hashVal = stoi(bidId);
int key = hash(hashVal);
if(bids.at(key).size() > 0){
list<Bid>::const_iterator k;
for(k = bids.at(key).begin(); k
!= bids.at(key).end(); k++ ){
if(k->bidId.compare(bidId) == 0){
k = bids.at(key).erase(k);
}
}
}
}
/**
* Search for the specified bidId
*
* @param bidId The bid id to search for
*/
Bid HashTable::Search(string bidId) {
Bid bid;
//Implement logic to search for and return a bid
int hashVal = stoi(bidId);
int key = hash(hashVal);
if(bids.at(key).size() > 0){
list<Bid>::const_iterator k;
for(k = bids.at(key).begin(); k != bids.at(key).end(); k++ ){
if(k->bidId.compare(bidId) == 0){
return *k;
}
}
}
return bid;
}
Implementation of Hash Table in Main Method
// Define a hash table to hold all the bids
HashTable* bidTable;
switch (choice) {
//Load Bids
case 1:
bidTable = new HashTable();
// Initialize a timer variable before loading bids
ticks = clock();
// Complete the method call to load the bids
loadBids(csvPath, bidTable);
// Calculate elapsed time and display result
ticks = clock() - ticks;
// current clock ticks minus starting clock ticks
cout << "time: " << ticks
<< " clock ticks" << endl;
cout << "time: "
<< ticks * 1.0 / CLOCKS_PER_SEC << " seconds" << endl;
break;
//Print all bids
case 2:
bidTable->PrintAll();
break;
//Search bids
case 3:
ticks = clock();
bid = bidTable->Search(bidKey);
ticks = clock() - ticks;
// current clock ticks minus starting clock ticks
if (!bid.bidId.empty()) {
displayBid(bid);
} else {
cout << "Bid Id " << bidKey << " not found." << endl;
}
cout << "time: " << ticks << "
clock ticks" << endl;
cout << "time: " << ticks * 1.0
/ CLOCKS_PER_SEC << " seconds" << endl;
break;
//Remove bids
case 4:
bidTable->Remove(bidKey);
break;
}
}
cout << "Good bye." << endl;
return 0;
}